Ansor论文笔记
Ansor: Generating High-Performance Tensor Programs for Deep Learning (OSDI 2020)
概述
Ansor是一个用于深度学习应用的张量程序生成框架。与现有的搜索策略相比,Ansor 通过从搜索空间的分层表示中采样程序来探索更多的优化组合。Ansor 通过启发式搜索和经过学习的成本模型对采样的程序进行调优,以优化程序性能、获得最佳程序。Ansor 可以生成现有最先进方法搜索空间外的高性能程序。此外,Ansor利用任务调度程序同时优化深度神经网络中的多个子图,以提高神经网络的端到端性能。
研究现状
模板引导的搜索
编译器要求用户为特定计算手动编写一个定义了张量程序结构的模板,该模板中包含若干可调节参数。随后,编译器负责寻找这些参数的最优配置。
TVM通过其模板引导搜索框架AutoTVM实现了模板搜索功能,并且已经可以实际应用。
- 开发优化模板本身是一项庞大而复杂的工程任务。
- 对开发人员提出了极高的要求,并需要大量的研究努力。
FlexTensor提出了一种通用模板设计。
- 但其适用范围限于单个算子,不适合于涉及多个算子的优化场景。

基于序列构造的搜索
基于序列构造的搜索策略通过将程序的构建过程解构为一系列预设的决策点来界定其搜索空间。编译器随后采用beamsearch等来遍历这些决策点,以寻找优化的程序构建路径。
例如Halide,编译器通过按顺序展开计算图中的节点,逐步构建出一个张量程序。每一决策步骤仅保留得分最高的前k个候选程序,以减少分支数量,通过一个训练好的的成本模型选择性能最优的候选,而其他被剪枝。
- 在搜索过程中,候选程序往往是不完整的,因为它们可能只展开了计算图的一部分或仅做出了部分决策,这可能导致搜索过程陷入局部最优解。
- 成本模型通常只能在完整程序上进行训练,将其直接应用于评估不完整程序的潜在性能会引入误差,并且基于序列的构造模式会积累这个误差。

问题描述
如何自动构建一个足够大的搜索空间:
- 现有方法搜索空间有限 / 未能完全实现自动化
- 层次化采样
如何高效搜索:
- 现有方法搜索效率低
- 进化搜索+成本模型,任务调度
如何为多个子图的搜索任务分配资源:
- 现有方法为子图分配相同的搜索时间,浪费资源
- 任务调度,为性能瓶颈子图分配更多资源
主要方法
Ansor的整体架构如图,主要包括程序采样器、性能调优器和任务调度器三部分。
Ansor的输入是一组待优化的深度神经网络,任务调度器使用Relay中的算子融合算法将DNNs从流行的模型格式转换为划分的小子图,然后程序采样器为这些子图进行采样生成张量程序,最后由性能调优器优化这些生成的张量程序。
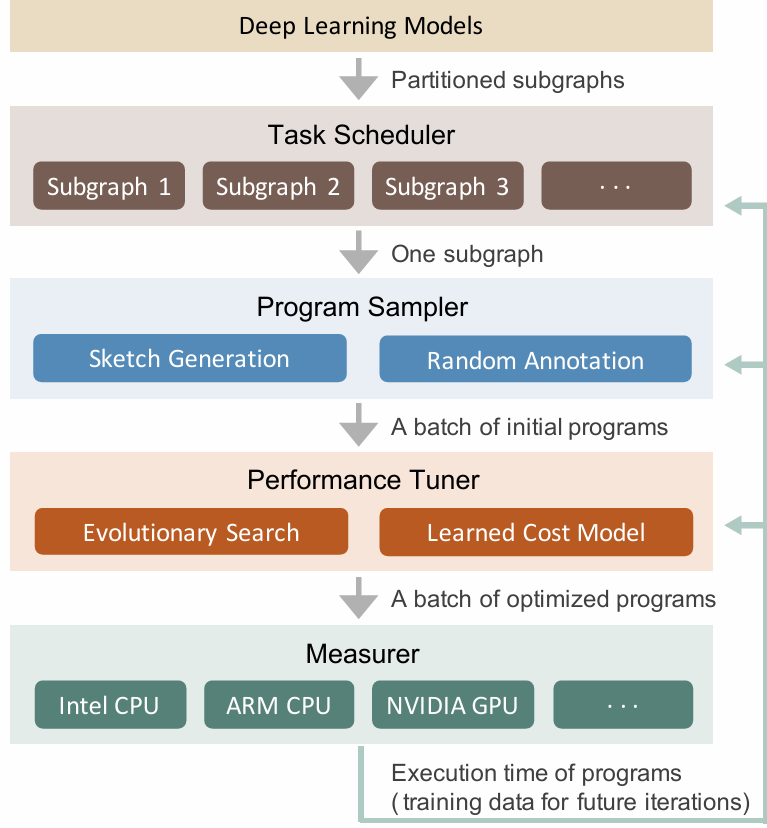
Ansor三个主要组成部分的作用:
- 程序采样器,它构建一个大型搜索空间并从中采样多样化的程序;
- 性能调优器,用于微调采样程序的性能;
- 任务调度器,为在DNNs中优化多个子图分配时间资源。
程序采样器
Ansor面临的一个关键挑战是为给定的计算图生成一个大型搜索空间。为了覆盖具有各种高层结构和低层细节的多样化张量程序,Ansor利用了一个具有两个层级的搜索空间的分层表示:sketch和annotation。Ansor将程序的高层结构定义为sketch,并将数十亿个低层选择(例如,平铺大小、并行、展开)作为annotation。这种表示允许Ansor灵活地枚举高层结构并高效地采样低层细节。
sketch generation
生成sketch即通过不同顺序应用一定的高层次优化规则。Ansor使用的一部分基本规则如表所示。
| 规则 | 条件 | 应用 |
|---|---|---|
| 跳过 | \(\neg IsStrictInlinable(S, i)\) | \(S' = S; i' = i - 1\) |
| 内联 | \(IsStrictInlinable(S, i)\) | \(S' = Inline(S, i)\); \(i' = i - 1\) |
| 多级块 | \(HasDataReuse(S, i)\) | \(S' = MultiLevelTiling(S, i); i' = i - 1\) |
| 块合并 | \(HasDataReuse(S, i) \wedge HasFusibleConsr(S, i)\) | \(S' = FuseConsr(MultiLevelTiling(S, i),i); i' = i - 1\) |
| 添加缓存 | \(HasDataReuse(S, i) \wedge \neg HasFusibleConsumer(S, i)\) | \(S' = AddCacheWrite(S, i); i = i'\) |
| 归约 | \(HasMoreReductionParallel(S, i)\) | \(S' = AddRfactor(S, i); i' = i - 1\) |
| 自定义 | … | … |
Ansor提出了一种基于推导的枚举方法,通过递归应用几个基本规则生成所有可能的sketch。该过程以子图数学表达式的有向无环图(DAG)作为输入,返回一个sketch列表。Ansor定义状态 \(\sigma = (S, i)\),其中 \(S\) 是有向无环图的当前部分生成的sketch,\(i\) 是当前工作节点的索引。有向无环图中的节点按从输出到输入的拓扑顺序排序。推导从初始朴素程序和最后一个节点开始,然后尝试递归地将所有推导规则应用于状态。对于每个规则,如果当前状态满足应用条件,Ansor将规则应用于 \(\sigma = (S, i)\),得到 \(\sigma' = (S', i')\),其中 \(i' \leq i\)。这样,索引 \(i\)(工作节点)单调递减。当 \(i=0\) 时,状态成为终止状态。在枚举过程中,可以对一个状态应用多个规则以生成多个后续状态。一个规则也可以生成多个可能的后续状态。因此,Ansor维护一个队列来存储所有中间状态。当队列为空时,过程结束。在sketch生成结束时,所有终止状态中的 \(\sigma.S\), 形成一个生成的sketch结果列表。对于大多数典型的子图,sketch的数量少于10个。
random annotation
sketch决定程序的结构,annotation决定程序的具体细节。sketch是不完整的程序,比如对于块结构而言,其没有具体的块大小和循环annotation(例如并行、展开和矢量化)。在本步骤中,程序采样器对sketch进行annotation,使它们成为完整的程序,使得能够进行调优和评估。给定一组生成的sketch,程序采样器随机选择其中一个,随机填写块大小等细节,随机进行类似于并行化、矢量化的annotation操作。此处的“随机”都指的是在所有有效值上的均匀分布。张量程序的随机采样如图所示。

性能调优器
随机采样的程序性能有限,需要进行调优。Ansor采用进化搜索迭代地获取新的张量程序,然后通过成本模型选择进化种群(即张量程序集合),不断迭代以获取最优的张量程序。
进化搜索
Ansor通过进化搜索(遗传算法)来构建从原始程序到最终程序的优化过程。进化搜索通过变异和杂交来调整程序。例如随机改变块大小、并行粒度称为变异,随机选取节点拼接到另一个合法的程序节点上称为杂交。这些操作执行非顺序重写,并解决了顺序构建的限制。Ansor中的进化操作专门为张量程序设计。它们可以应用于一般张量程序,并且可以处理具有复杂依赖关系的搜索空间。

成本模型
成本模型的引入可以有效降低进化搜索时对张量程序的评估时间,能够帮助Ansor从搜索空间中快速识别性能好的张量程序。
任务调度器
为了降低搜索时间,需要为由编译器经大型计算图分割而成的子图分配时间资源。对于一些子图,花费时间进行调优并不能显著改善端到端的DNN性能。这是由于两个原因:(1)子图不是性能瓶颈,(2)调优仅在子图的性能上带来微小改进。 为了避免在调优不重要的子图上浪费时间资源,Ansor动态分配不同数量的时间资源给不同的子图。Ansor的任务调度器以迭代方式为任务分配时间资源。

Ansor为输入的神经网络设计了迭代过程。在每次迭代中,Ansor选择一个子图,为子图生成一批有希望的程序,并在硬件上测量程序。Ansor将这样的迭代定义为单位时间资源。当Ansor将一个单位的时间资源分配给一个任务时,该任务获得生成和测量新程序的机会,这也意味着找到更好程序的机会,如图所示。Ansor的任务调度过程就是为整个神经网络的所有子图应用基于梯度下降的调度算法,将资源分配给更有可能提高端到端性能的子图。

实验评估
实验对Ansor进行了全面评估,包括性能、搜索效率和任务调度的有效性。Ansor从单算子到子图再到整个神经网络的不同规模的张量程序进行了评估,并且进行了相关的消融实验,具体不在此详细记录。Ansor还与TVM在相同任务下达到相同性能进行了比较,证明了效率上的提升(任务调度的有效)。
总结
Ansor成功找到了高性能张量程序。在各种神经网络和硬件平台上,Ansor在性能上超过了现有的内核库和基于搜索的框架。Ansor目前已集成到TVM中。
Ansor的限制:
- Ansor无法优化具有动态形状的图:Ansor要求计算图中的形状是静态的并且在分析、构建搜索空间和执行测量之前就已知的,如何为符号或动态形状生成程序是未来的一个方向。
- Ansor只支持密集运算符:为了支持常用于稀疏神经网络和图神经网络中的稀疏运算符(例如SpMM),需要重新设计搜索空间。
- Ansor只在高层次上执行程序优化,但依赖于其他代码生成器(例如LLVM和NVCC)来进行平台相关的优化。