OSPF 协议实现
本实验实现了OSPFv2协议的基本功能,包括邻接关系的建立、链路状态数据库的同步、最短路径和路由表的计算等。通过模拟实验环境和真实网络环境,验证了OSPF协议实现的正确性和可靠性。
项目设计
总计架构设计
.
├── docs/
├── gns3/
├── makefile
├── readme.md
├── src/
│ ├── interface.cpp
│ ├── interface.hpp
│ ├── lsdb.cpp
│ ├── lsdb.hpp
│ ├── main.cpp
│ ├── neighbor.cpp
│ ├── neighbor.hpp
│ ├── packet.cpp
│ ├── packet.hpp
│ ├── route.cpp
│ ├── route.hpp
│ ├── transit.cpp
│ ├── transit.hpp
│ └── utils.hpp
├── style.sh
└── xmake.lua
本项目的文件和代码结构如下:
./docs:文档./gns3:GNS3配置文件./src:OSPF实现源码packet:各类OSPF报文和LSA数据结构、收发报文处理interface:接口数据结构、接口状态和事件lsdb:链路状态数据库类neighbor:邻接数据结构、邻接状态和事件route:路由表数据结构、路由表更新、最短路算法transit:recv和send线程utils:工具函数
xmake.lua和makefile:编译配置文件
数据结构设计
OSPF包数据格式
OSPF包含5种类型的报文,分别是Hello、Database Description(DD)、Link State Request(LSR)、Link State Update(LSU)和Link State Acknowledgment(LSAck),报文的结构定义参考RFC 2328的附录A3,每种报文的数据结构如下:
namespace OSPF {
/* OSPF packet types. */
enum struct Type : uint8_t {
HELLO = 1,
DD,
LSR,
LSU,
LSACK
};
/* OSPF packet header structure. */
struct Header {
uint8_t version;
Type type;
uint16_t length;
in_addr_t router_id;
in_addr_t area_id;
uint16_t checksum;
uint16_t auth_type;
uint64_t auth;
void host_to_network() noexcept;
void network_to_host() noexcept;
} __attribute__((packed));
/* OSPF hello packet structure. */
struct Hello {
in_addr_t network_mask;
uint16_t hello_interval;
uint8_t options;
uint8_t router_priority;
uint32_t router_dead_interval;
in_addr_t designated_router;
in_addr_t backup_designated_router;
in_addr_t neighbors[0];
void host_to_network(size_t nbr_num) noexcept;
void network_to_host() noexcept;
} __attribute__((packed));
/* OSPF database description packet structure. */
struct DD {
uint16_t interface_mtu;
uint8_t options;
uint8_t flags;
#define DD_FLAG_MS 0x01
#define DD_FLAG_M 0x02
#define DD_FLAG_I 0x04
#define DD_FLAG_ALL DD_FLAG_MS | DD_FLAG_M | DD_FLAG_I
uint32_t sequence_number;
LSA::Header lsahdrs[0];
void host_to_network(size_t lsahdrs_num) noexcept;
void network_to_host() noexcept;
} __attribute__((packed));
/* OSPF link state request packet structure. */
struct LSR {
struct Request {
uint32_t ls_type;
uint32_t link_state_id;
uint32_t advertising_router;
void host_to_network() noexcept;
void network_to_host() noexcept;
bool operator==(const Request& rhs) const;
} reqs[0];
void host_to_network(size_t reqs_num) noexcept;
void network_to_host() noexcept;
} __attribute__((packed));
/* OSPF link state update packet structure. */
struct LSU {
uint32_t num_lsas;
// LSA是不定长的,很难在这里定义多个LSA
// 将多个LSA的管理交给调用者
void host_to_network() noexcept;
void network_to_host() noexcept;
} __attribute__((packed));
/* OSPF link state acknowledgment packet structure. */
struct LSAck {
LSA::Header lsahdrs[0];
} __attribute__((packed));
} // namespace OSPF
其中__attribute__((packed))是为了保证结构体的字节对齐,用于在收到和发送报文时直接使用强制类型转换,用以正确解释内存。
类似LSA::Header lsahdrs[0];的结构用于表示不定长结构,不使用std::list和std::vector等堆分配的数据结构以进行强制类型转换。直接在结构体中定义一个长度为0的数组,然后在使用时通过指针的方式访问该结构体内存的偏移量,然后用memcpy等函数进行拷贝。注意这个方式需要将-Wall编译选项关闭,否则会因警告造成编译失败。
LSA数据格式
OSPFv2中有5种LSA,分别是Router LSA、Network LSA、Summary LSA、ASBR Summary LSA和External LSA,分别用于描述路由器、网络、汇总、ASBR和外部路由信息。根据RFC 2328的附录A4,LSA的数据结构如下:
namespace LSA {
/* LSA types. */
enum struct Type : uint8_t {
ROUTER = 1,
NETWORK,
SUMMARY,
ASBR_SUMMARY,
AS_EXTERNAL
};
/* LSA header structure. */
struct Header {
uint16_t age;
uint8_t options;
Type type;
in_addr_t link_state_id;
in_addr_t advertising_router;
uint32_t sequence_number;
uint16_t checksum;
uint16_t length;
void host_to_network() noexcept;
void network_to_host() noexcept;
bool operator==(const Header& rhs) const;
} __attribute__((packed));
/* Router-LSA Link types. */
enum class LinkType : uint8_t {
POINT2POINT = 1,
TRANSIT,
STUB,
VIRTUAL
};
/* Base LSA structure. */
struct Base {
Header header;
virtual size_t size() const = 0;
virtual void to_packet(char *packet) const;
virtual void make_checksum() = 0;
bool operator<(const Base& rhs) const;
bool operator>(const Base& rhs) const;
};
/* Router-LSA structure. */
struct Router : public Base {
/* Router-LSA Link structure. */
struct Link {
in_addr_t link_id;
in_addr_t link_data;
LinkType type;
uint8_t tos;
uint16_t metric;
Link() = default;
Link(in_addr_t link_id, in_addr_t link_data, LinkType type, uint16_t metric);
Link(char *net_ptr);
} __attribute__((packed));
uint16_t flags;
uint16_t num_links;
std::vector<Link> links;
Router() = default;
Router(char *net_ptr);
size_t size() const override;
void make_checksum() override;
bool operator==(const Router& rhs) const;
};
/* Network-LSA structure. */
struct Network : public Base {
in_addr_t network_mask;
std::vector<in_addr_t> attached_routers;
Network() = default;
Network(char *net_ptr);
size_t size() const override;
void to_packet(char *packet) const override;
void make_checksum() override;
bool operator==(const Network& rhs) const;
};
/* Summary-LSA structure. */
struct Summary : public Base {
in_addr_t network_mask;
// union {
// uint8_t tos;
// uint32_t metric;
// };
uint8_t tos;
uint32_t metric; // 实际上是24位的一个字段,需要特殊处理
Summary(char *net_ptr);
size_t size() const override;
void to_packet(char *packet) const override;
void make_checksum() override;
};
/* ASBR-summary-LSA structure. */
// ASBR-summary-LSA = Summary-LSA except for ls type
/* AS-external-LSA structure. */
struct ASExternal : public Base {
in_addr_t network_mask;
struct ExternRoute {
uint8_t tos;
#define AS_EXTERNAL_FLAG 0x01
uint32_t metric; // 同样是24位的一个字段
in_addr_t forwarding_address;
uint32_t external_router_tag;
};
std::vector<ExternRoute> e;
ASExternal(char *net_ptr);
size_t size() const override;
void to_packet(char *packet) const override;
};
} // namespace LSA
using RouterLSA = LSA::Router;
using NetworkLSA = LSA::Network;
using SummaryLSA = LSA::Summary;
using ASBRSummaryLSA = LSA::Summary;
using ASExternalLSA = LSA::ASExternal;
其中LSA Header采用了和OSPF报文相同的紧密字节对齐方式,而派生的LSA结构体采用了面向对象的模式。这么设计是考虑到以下实践:
- LSA的Header部分在收发报文时需要频繁判断类型,此过程不需要进行网络序和主机序的转换,直接用强制类型转换的方式判断即可;
- LSA本身信息只有在计算路由时会用到,因此在收发报文时不需要对LSA的具体内容进行解析,通过构造函数和
to_packet函数实现实现不同LSA的序列化和反序列化,使用一些堆区分配的数据结构可以使得访问和管理更加方便。
Summary-LSA和ASBR-Summary-LSA定义是完全一致的,因此直接使用Summary-LSA即可。Summary-LSA和AS-external-LSA中的metric字段是24位的,需要特殊处理。
接口数据结构
接口表示路由器上可以用于收发报文的设备,用以连接路由器和网络,每个OSPF接口接入各自的网络/子网,可以认为接口属于包含其接入网络的区域,由路由器发出的LSA反映其状态和相关联的邻接。根据RFC 2328的第9节,接口的数据结构如下:
class Interface {
public:
/* 接口的类型 */
enum class Type {
P2P = 1,
BROADCAST,
NBMA,
P2MP,
VIRTUAL
} type = Type::BROADCAST;
/* 接口的功能层次 */
enum class State {
DOWN,
LOOPBACK,
WAITING,
POINT2POINT,
DROTHER,
BACKUP,
DR
} state = State::DOWN;
/* 接口ip地址 */
in_addr_t ip_addr;
/* 接口子网掩码 */
in_addr_t mask;
/* 区域标识 */
uint32_t area_id;
/* 从该接口发送Hello报文的时间间隔 */
uint32_t hello_interval = 10;
/* 当不再收到路由器的Hello包后,宣告邻居断开的时间间隔 */
uint32_t router_dead_interval = 40;
/* 向该接口的邻接重传LSA的时间间隔 */
uint32_t rxmt_interval = 5;
/* 接口上发送一个LSU包所需要的大致时间 */
uint32_t intf_trans_delay = 1;
/* 路由器优先级 */
uint8_t router_priority = 1;
/* Hello计时器 */
uint32_t hello_timer = 0;
/* Wait计时器 */
uint32_t wait_timer = 0;
/* 该接口的邻接路由器 */
std::list<Neighbor *> neighbors;
/* 选举出的DR */
in_addr_t designated_router = 0;
/* 选举出的BDR */
in_addr_t backup_designated_router = 0;
/* 接口输出值,即在Router-LSA中宣告的连接状态距离值 */
uint32_t cost = 1;
/* 验证类型 */
uint16_t auth_type;
/* 验证密码 */
uint64_t auth_key;
/* 接口名称 */
char name[IFNAMSIZ];
/* 接口index */
int if_index;
public:
/* 改变接口状态的事件 */
void event_interface_up();
void event_wait_timer();
void event_backup_seen();
void event_neighbor_change();
void event_loop_ind();
void event_unloop_ind();
void event_interface_down();
Neighbor *get_neighbor_by_id(in_addr_t id);
Neighbor *get_neighbor_by_ip(in_addr_t ip);
public:
/* loop fd,不在构造函数中初始化,避免抛出异常 */
int send_fd;
int recv_fd;
public:
Interface() = default;
Interface(in_addr_t ip_addr, in_addr_t mask, uint32_t area_id) : ip_addr(ip_addr), mask(mask), area_id(area_id) {
}
~Interface();
private:
/* 选举DR和BDR */
void elect_designated_router();
};
接口中存储了接口收发报文以及邻居管理的一些必要信息。接口有类型字段,表示的是接入网络的类型,在本实验中主要为广播类型。接口的状态由一定的时间进行转移,反映了接口的工作情况和职责。
DR和BDR的选举是通过接口的elect_designated_router函数实现的,该函数会在接口状态改变时调用,通过比较邻接路由器的优先级和IP地址来选举DR和BDR。选举的结果会在接口的designated_router和backup_designated_router字段中记录。
接口的信息实际上是需要在路由器的Console中用命令行配置的,但本实验用主机模拟路由器功能,因此在本项目中实现了接口动态读取的功能,通过init_interfaces实现:
void init_interfaces() {
int fd = socket(AF_INET, SOCK_DGRAM, 0);
if (fd < 0) {
exit(EXIT_FAILURE);
}
ifreq ifr[MAX_INTERFACE_NUM];
ifconf ifc;
ifc.ifc_len = sizeof(ifr);
ifc.ifc_req = ifr;
if (ioctl(fd, SIOCGIFCONF, &ifc) < 0) {
close(fd);
exit(EXIT_FAILURE);
}
int num_ifr = ifc.ifc_len / sizeof(ifreq);
for (auto i = 0; i < num_ifr; ++i) {
if (strstr(ifr->ifr_name, "lo") != nullptr || strstr(ifr->ifr_name, "docker") != nullptr) {
continue;
}
// fetch interface name, ip addr, mask
auto intf = new Interface();
strncpy(intf->name, ifr->ifr_name, IFNAMSIZ);
if (ioctl(fd, SIOCGIFADDR, ifr) < 0) {
perror("ioctl SIOCGIFADDR");
delete intf;
continue;
}
intf->ip_addr = ntohl(((sockaddr_in *)&ifr->ifr_addr)->sin_addr.s_addr);
if (ioctl(fd, SIOCGIFNETMASK, ifr) < 0) {
perror("ioctl SIOCGIFNETMASK");
delete intf;
continue;
}
intf->mask = ntohl(((sockaddr_in *)&ifr->ifr_addr)->sin_addr.s_addr);
intf->area_id = 0;
// fetch interface index
if (ioctl(fd, SIOCGIFINDEX, ifr) < 0) {
perror("ioctl SIOCGIFINDEX");
delete intf;
continue;
}
intf->if_index = ifr->ifr_ifindex;
// turn on promisc mode
if (ioctl(fd, SIOCGIFFLAGS, ifr) < 0) {
perror("ioctl SIOCGIFFLAGS");
delete intf;
continue;
}
ifr->ifr_flags |= IFF_PROMISC;
if (ioctl(fd, SIOCSIFFLAGS, ifr) < 0) {
perror("ioctl SIOCSIFFLAGS");
delete intf;
continue;
}
// alloc send fd
int socket_fd;
ifreq socket_ifr;
if ((socket_fd = socket(AF_INET, SOCK_RAW, IPPROTO_OSPF)) < 0) {
perror("send socket_fd init");
delete intf;
continue;
}
memset(&socket_ifr, 0, sizeof(ifreq));
strcpy(socket_ifr.ifr_name, intf->name);
if (setsockopt(socket_fd, SOL_SOCKET, SO_BINDTODEVICE, &socket_ifr, sizeof(ifreq)) < 0) {
perror("send_loop: setsockopt");
delete intf;
continue;
}
intf->send_fd = socket_fd;
// alloc recv fd
if ((socket_fd = socket(AF_PACKET, SOCK_RAW, htons(ETH_P_IP))) < 0) {
perror("recv socket_fd init");
delete intf;
continue;
}
memset(&socket_ifr, 0, sizeof(ifreq));
strcpy(socket_ifr.ifr_name, intf->name);
if (setsockopt(socket_fd, SOL_SOCKET, SO_BINDTODEVICE, &socket_ifr, sizeof(ifreq)) < 0) {
perror("recv_loop: setsockopt");
delete intf;
continue;
}
intf->recv_fd = socket_fd;
// add to interfaces
this_interfaces.push_back(intf);
}
close(fd);
std::cout << "Found " << this_interfaces.size() << " interfaces." << std::endl;
for (auto intf : this_interfaces) {
std::cout << "Interface " << intf->name << ":" << std::endl
<< "\tip addr:" << ip_to_str(intf->ip_addr) << std::endl
<< "\tmask:" << ip_to_str(intf->mask) << std::endl;
intf->hello_timer = 0;
intf->wait_timer = 0;
intf->event_interface_up();
}
}
通过ioctl函数获取接口的IP地址、子网掩码、接口名和索引等信息,然后通过socket函数创建接口的发送和接收套接字,通过setsockopt函数将套接字绑定到接口上,实现接口的数据收发。注意需要排除本地回环接口和docker接口,因为这些接口不参与OSPF协议的实现。
邻接数据结构
邻接表示路由器之间的相邻关系,每个会话被限定在特定的路由器接口上,并由邻居的OSPF路由器标识。根据RFC 2328的第10节,邻接的数据结构如下:
class Neighbor {
public:
/* 邻居的状态 */
enum class State {
DOWN = 0,
ATTEMPT,
INIT,
TWOWAY,
EXSTART,
EXCHANGE,
LOADING,
FULL
} state = State::DOWN;
/* 非活跃计时器 */
uint32_t inactivity_timer = 40;
/* 是否为master */
bool is_master = false;
/* DD包的序列号 */
uint32_t dd_seq_num;
/* 最后一个DD包,用于重传 */
uint32_t recv_dd_seq_num;
/* 最后一个发出的DD包的长度和数据 */
uint32_t last_dd_data_len;
char last_dd_data[ETH_DATA_LEN];
/* 记录上一次传输的dd包中lsahdr的数量 */
size_t dd_lsahdr_cnt = 0;
/* 是否收到了!FLAG_M的DD包 */
bool dd_recv_no_more = false;
/* 邻居的路由器标识 */
uint32_t id;
/* 邻居的优先级 */
uint32_t priority;
/* 邻居的IP地址 */
in_addr_t ip_addr;
/* 邻居的指定路由器 */
in_addr_t designated_router;
/* 邻居的备份指定路由器 */
in_addr_t backup_designated_router;
Interface *host_interface;
/* 邻居的重传计时器 */
uint32_t rxmt_timer = 0;
/* 需要重传的链路状态数据 */
std::list<LSA::Base *> link_state_rxmt_list;
/* Exchange状态下的链路状态数据 */
std::list<LSA::Header *> db_summary_list; // 不会被同时访问,不需要加锁
std::list<LSA::Header *>::iterator db_summary_send_iter;
/* Exchange和Loading状态下需要请求的链路状态数据 */
std::list<OSPF::LSR::Request> link_state_request_list;
std::mutex link_state_request_list_mtx; // 因为exchange阶段就在发lsr了,会被同时访问
/* Exchange和Loading状态下收到的链路状态请求,准备用于lsu中发送 */
std::list<LSA::Base *> lsa_update_list;
/* 邻居DD选项 */
uint8_t dd_options;
/* 向邻居发送的DD包,Init标志 */
bool dd_init = true;
public:
Neighbor(in_addr_t ip_addr, Interface *interface) : ip_addr(ip_addr), host_interface(interface) {
// dd_rtmx = false;
// dd_ack = false;
}
~Neighbor() = default;
public:
void event_hello_received();
void event_start();
void event_2way_received();
void event_negotiation_done();
void event_exchange_done();
void event_bad_lsreq();
void event_loading_done();
void event_adj_ok();
void event_seq_number_mismatch();
void event_1way_received();
void event_kill_nbr();
void event_inactivity_timer();
void event_ll_down();
private:
bool estab_adj() noexcept;
};
接口中存储了接口收发报文以及邻居管理的一些必要信息。邻居有状态字段,表示的是邻居的状态,根据OSPF协议的状态机,邻居的状态会随着事件的发生而改变,如收到Hello报文、超时等,这些事件会改变邻居的状态,从而影响邻居的行为。
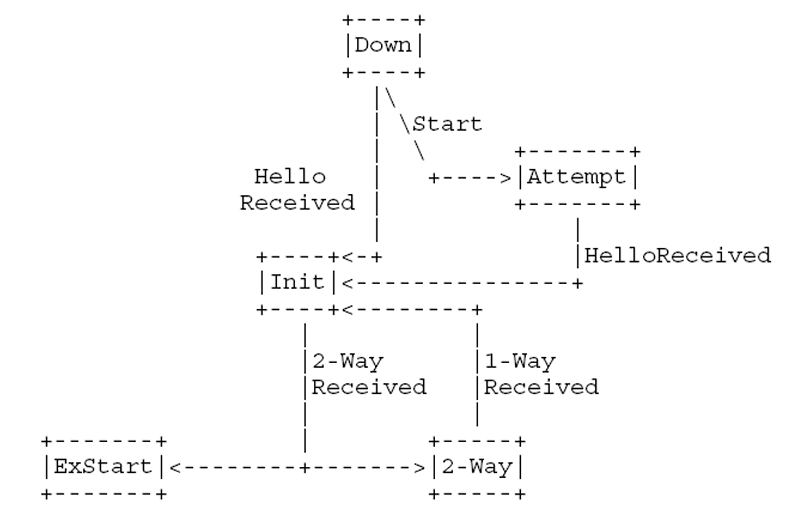
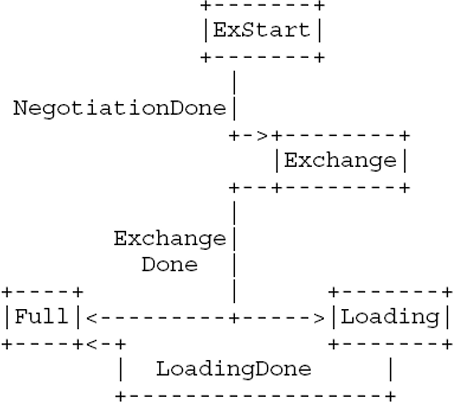
邻居状态机是整个OSPF协议的核心,通过邻居状态机的状态转移来实现邻接的建立和链路状态的同步。完整的邻居状态机如图下面两张图片所示:
由Hello报文触发:
由数据库更新触发:
项目实现
邻接关系建立
建立邻接关系的核心是Hello报文的处理。通过Hello报文发现邻接路由器,邻居状态机从Down进入Init状态。
再收到Hello报文后,如果邻居的Hello报文中包含自己,就根据网络类型进入2-Way或ExStart状态。前者代表不需要建立邻接关系,会保持2-way状态并持续等待adj_ok?事件;后者代表需要建立邻接关系,接口会进行选举。
void process_hello(Interface *intf, char *ospf_packet, in_addr_t src_ip) {
auto ospf_hdr = reinterpret_cast<OSPF::Header *>(ospf_packet);
auto ospf_hello = reinterpret_cast<OSPF::Hello *>(ospf_packet + sizeof(OSPF::Header));
// auto nbr = intf->get_neighbor(src_ip);
// if (nbr == nullptr) {
// nbr = intf->add_neighbor(src_ip);
// }
Neighbor *nbr = intf->get_neighbor_by_ip(src_ip);
if (nbr == nullptr) {
nbr = new Neighbor(src_ip, intf);
intf->neighbors.push_back(nbr);
}
nbr->id = ospf_hdr->router_id; // hdr已经是host字节序
auto prev_ndr = nbr->designated_router;
auto prev_nbdr = nbr->backup_designated_router;
nbr->designated_router = ntohl(ospf_hello->designated_router);
nbr->backup_designated_router = ntohl(ospf_hello->backup_designated_router);
nbr->priority = ntohl(ospf_hello->router_priority);
nbr->event_hello_received();
auto to_2way = false;
// 1way/2way: hello报文中的neighbors列表中是否包含自己
in_addr_t *attached_nbr = ospf_hello->neighbors;
while (attached_nbr != reinterpret_cast<in_addr_t *>(ospf_packet + ospf_hdr->length)) {
if (*attached_nbr == inet_addr(THIS_ROUTER_ID)) {
to_2way = true;
break;
}
attached_nbr++;
}
if (to_2way) {
// 邻居的Hello报文中包含自己,触发2way事件
// 如果在这里需要建立邻接,邻接会直接进入exstart状态
// 否则会进入并维持在2way状态,等待adj_ok事件
nbr->event_2way_received();
} else {
nbr->event_1way_received();
return;
}
if (nbr->designated_router == nbr->ip_addr && nbr->backup_designated_router == 0 &&
intf->state == Interface::State::WAITING) {
// 如果邻居宣称自己是DR,且自己不是BDR
intf->event_backup_seen();
} else if ((prev_ndr == nbr->ip_addr) ^ (nbr->designated_router == nbr->ip_addr)) {
intf->event_neighbor_change();
}
if (nbr->backup_designated_router == nbr->ip_addr && intf->state == Interface::State::WAITING) {
// 如果邻居宣称自己是BDR
intf->event_backup_seen();
} else if ((prev_nbdr == nbr->ip_addr) ^ (nbr->backup_designated_router == nbr->ip_addr)) {
intf->event_neighbor_change();
}
}
链路状态数据库同步
Exstart和Exchange状态
在ExStart状态下,选举出Master和Slave,这里rfc2328写的并不是很详细。在初始的时候,会给邻接数据结构一个设定的dd_seq_num值。
主从关系的确立的核心认可主从关系。对两个路由器而言,最初都认为自己是Master。这时如果一个路由器发现对方发送的、带有I、M、MS标志位的DD报文的Router ID比自己的大,就会认可自己是Slave,并将自己的dd_seq_num改为对方的值,进入Exchange状态;如果不然,这个DD报文会被忽略,这个时候未来会成为Master的这个路由器并没有认可自己为Master。
在Slave认可主从关系后,会回应一个不带有I、MS标志位的DD报文,这个报文(一般)会带有自己数据库的摘要信息,即LSA Header(这一点需要抓包才能看出来,标准中略过了这里的细节)。路由器接收到这个不带有I、MS标志位的DD报文,并且发现其中的dd_seq_num和自己相同(Slave已经认可了主从关系),且对方Router ID小于自己,就认可自己为Master,进入Exchange状态。需要注意的是,需要处理这个DD报文中的摘要信息。
在Exchange阶段,只有Master能够主动发送DD报文,并且超时重传。Slave只能在接收到Master的DD报文后立即回复。而且,Master只有在收到了希望接收的DD报文后才能发送下一个DD报文,否则等待超时重传。相应的是,如果两边报文都合理接收的话,这一阶段是没有等待的。
需要注意的是,当Slave已经收到了不含M标志位的报文,在发送DD报文时发现没有LSA需要发送,就会进入Loading状态或Full状态。而Master在收到不含M标志位的报文后,发现自己的db_summary_list为空,就会进入Loading或Full状态。此处Slave状态切换一定会先于Master。
size_t produce_dd(char *body, Neighbor *nbr) {
auto dd = reinterpret_cast<OSPF::DD *>(body);
size_t dd_len;
dd->interface_mtu = ETH_DATA_LEN;
dd->options = 0x02;
dd->sequence_number = nbr->dd_seq_num;
dd->flags = 0;
if (!nbr->is_master) {
dd->flags |= DD_FLAG_MS;
}
if (nbr->dd_init) {
dd->flags |= DD_FLAG_I;
}
dd_len = sizeof(OSPF::DD);
if (nbr->dd_init) {
dd->host_to_network(0);
} else {
auto lsahdr = dd->lsahdrs;
if (nbr->db_summary_list.size() > dd_max_lsahdr_num) {
std::advance(nbr->db_summary_send_iter, dd_max_lsahdr_num);
dd->flags |= DD_FLAG_M;
for (auto it = nbr->db_summary_list.begin(); it != nbr->db_summary_send_iter; ++it) {
memcpy(lsahdr, *it, sizeof(LSA::Header));
lsahdr++;
}
dd_len += sizeof(LSA::Header) * dd_max_lsahdr_num;
dd->host_to_network(dd_max_lsahdr_num);
} else {
// 本次发送剩下所有lsahdr
nbr->db_summary_send_iter = nbr->db_summary_list.end();
for (auto it = nbr->db_summary_list.begin(); it != nbr->db_summary_list.end(); ++it) {
memcpy(lsahdr, *it, sizeof(LSA::Header));
lsahdr++;
}
dd_len += sizeof(LSA::Header) * nbr->db_summary_list.size();
dd->host_to_network(nbr->db_summary_list.size());
// 如果slave已收到!M的包,而且无lsahdr需要发送
if (nbr->is_master && nbr->dd_recv_no_more) {
nbr->event_exchange_done();
nbr->db_summary_list.clear();
}
}
}
return dd_len;
}
void process_dd(Interface *intf, char *ospf_packet, in_addr_t src_ip) {
auto ospf_hdr = reinterpret_cast<OSPF::Header *>(ospf_packet);
auto ospf_dd = reinterpret_cast<OSPF::DD *>(ospf_packet + sizeof(OSPF::Header));
Neighbor *nbr = intf->get_neighbor_by_ip(src_ip);
assert(nbr != nullptr);
ospf_dd->network_to_host();
bool dup = nbr->recv_dd_seq_num == ospf_dd->sequence_number;
nbr->recv_dd_seq_num = ospf_dd->sequence_number;
bool accept = false;
switch (nbr->state) {
case Neighbor::State::DOWN:
case Neighbor::State::ATTEMPT:
case Neighbor::State::TWOWAY:
return;
case Neighbor::State::INIT:
nbr->event_2way_received();
if (nbr->state == Neighbor::State::TWOWAY) {
return;
}
// 如果变为exstart状态,直接进入下一个case
// 在此处不需要break
case Neighbor::State::EXSTART:
nbr->dd_options = ospf_dd->options;
if (ospf_dd->flags & DD_FLAG_ALL && nbr->id > ntohl(inet_addr(THIS_ROUTER_ID))) {
nbr->is_master = true;
nbr->dd_seq_num = ospf_dd->sequence_number;
} else if (!(ospf_dd->flags & DD_FLAG_MS) && !(ospf_dd->flags & DD_FLAG_I) &&
ospf_dd->sequence_number == nbr->dd_seq_num && nbr->id < ntohl(inet_addr(THIS_ROUTER_ID))) {
nbr->is_master = false;
} else {
// 将要成为master收到了第一个DD包,无需处理
return;
}
nbr->dd_init = false;
nbr->event_negotiation_done();
if (nbr->is_master) {
// 如果自己是slave,发送这样一个DD包:
// 1. MS和I位置0
// 2. 序列号为邻居的dd_seq_num
// 3. 包含lsahdr
// 此时已经是exchange状态,这很重要
nbr->last_dd_data_len = produce_dd(nbr->last_dd_data + sizeof(OSPF::Header), nbr);
send_packet(intf, nbr->last_dd_data, nbr->last_dd_data_len, OSPF::Type::DD, nbr->ip_addr);
return;
}
// 如果是master,这里收到dd包必然不为空
// 在切换到exchange状态后按照exchange状态的处理方式处理
// 这里不需要break
case Neighbor::State::EXCHANGE:
// 如果收到了重复的DD包
if (dup) {
if (nbr->is_master) {
// slave需要重传上一个包,master的重传通过计时器实现
send_packet(intf, nbr->last_dd_data, nbr->last_dd_data_len, OSPF::Type::DD, nbr->ip_addr);
}
return;
} else {
// 主从关系不匹配
if ((bool)(ospf_dd->flags & DD_FLAG_MS) != nbr->is_master) {
nbr->event_seq_number_mismatch();
return;
}
// 意外设定了I标志
if (ospf_dd->flags & DD_FLAG_I) {
nbr->event_seq_number_mismatch();
return;
}
}
// 如果选项域与过去收到的不一致
if (nbr->dd_options != ospf_dd->options) {
nbr->event_seq_number_mismatch();
return;
}
if (nbr->is_master && // 自己为 slave
ospf_dd->sequence_number == nbr->dd_seq_num + 1) { // 对于slave,下一个包应当是邻接记录的dd_seq_num + 1
nbr->dd_seq_num = ospf_dd->sequence_number;
accept = true;
} else if (!nbr->is_master && // 自己为master
ospf_dd->sequence_number == nbr->dd_seq_num) { // 对于master,下一个包应当为邻居记录的dd_seq_num
nbr->dd_seq_num += 1;
accept = true;
} else {
nbr->event_seq_number_mismatch();
return;
}
break;
case Neighbor::State::LOADING:
case Neighbor::State::FULL:
// 主从关系不匹配
if ((bool)(ospf_dd->flags & DD_FLAG_MS) != nbr->is_master) {
nbr->event_seq_number_mismatch();
return;
}
// 意外设定了I标志
if (ospf_dd->flags & DD_FLAG_I) {
nbr->event_seq_number_mismatch();
return;
}
// slave收到重复的DD包
if (nbr->is_master && dup) {
send_packet(intf, nbr->last_dd_data, nbr->last_dd_data_len, OSPF::Type::DD, nbr->ip_addr);
return;
}
break;
default:
break;
}
if (accept) {
// 视为回复,将db_summary_list中上一次发送的lsahdr删除(可能为空)
nbr->db_summary_list.erase(nbr->db_summary_list.begin(), nbr->db_summary_send_iter);
// 收到了!M的DD包
nbr->dd_recv_no_more = !(ospf_dd->flags & DD_FLAG_M);
// 将收到的lsahdr加入link_state_request_list
auto num_lsahdrs = (ospf_hdr->length - sizeof(OSPF::Header) - sizeof(OSPF::DD)) / sizeof(LSA::Header);
LSA::Header *lsahdr = ospf_dd->lsahdrs;
for (auto i = 0; i < num_lsahdrs; ++i) {
lsahdr->network_to_host();
nbr->link_state_request_list_mtx.lock();
this_lsdb.lock();
if (this_lsdb.get(lsahdr->type, lsahdr->link_state_id, lsahdr->advertising_router) == nullptr) {
nbr->link_state_request_list.push_back(
{(uint32_t)lsahdr->type, lsahdr->link_state_id, lsahdr->advertising_router});
}
this_lsdb.unlock();
nbr->link_state_request_list_mtx.unlock();
lsahdr++;
}
// 从本质上说,master和slave都需要立即回复
// master需要在此处完成exchange_done事件
if (!nbr->is_master) {
if (nbr->db_summary_list.empty() && nbr->dd_recv_no_more) {
nbr->event_exchange_done();
return;
}
}
nbr->last_dd_data_len = produce_dd(nbr->last_dd_data + sizeof(OSPF::Header), nbr);
send_packet(intf, nbr->last_dd_data, nbr->last_dd_data_len, OSPF::Type::DD, nbr->ip_addr);
}
}
Loading和Full状态
事实上,LSR包的构造在Exchange阶段就已经开始,当邻居数据结构中link_state_request_list不为空时,就应该构造并发送LSR包。路由器将连接状态请求列表的开始部分头部n个,包含在LSR包中发给邻居,来取得这些LSA。当邻居以适当的LSU包,回应了这些请求后,删减连接状态请求列表的头部n个,并发出新的LSR包。在实际实现中通过一个链表来管理link_state_request_list。继续这一过程,直到连接状态请求列表为空。那些在连接状态请求列表中,已经发出,但还没有收到的LSA,被包含在LSR包中,以RxmtInterval的周期重传。在任何时候,都至多发送一个LSR包。
当路由器收到LSR包时,应当在立即在路由器的数据库中检索LSR包中的每个LSA,并将其复制到LSU包中发往邻居。这些LSA不应当被放入邻居的连接状态重传列表中。如果某个LSA没有在数据库中被找到,说明在数据库交换过程中出错,应当生成BadLSReq邻居事件。
当邻居状态为Loading而连接状态请求列表为空时(也就是已经与邻居完整地收发了全部的DD包),生成 LoadingDone 邻居事件,由Loading进入Full状态。在Full状态下,邻居已经完全同步了数据库,视为已经完全建立了邻接关系。
建立一对邻接关系的完整过程如下:

DR和BDR选举
DR和BDR的选举参考RFC 2328的9.4节完成。
无论是接口数据结构、邻接数据结构或是Hello包中,DR和BDR字段记录的都是关联接口的IP地址,而不是路由器ID。
路由选举由接口状态机调用。当网络上的路由器第一次运行选举算法时,将网络上的 DR 和 BDR 都初始设置为 0.0.0.0,表示目前没有 DR 和 BDR 存在。选举算法的过程如下:执行选举的路由器称为 X,首先检查该网络上与路由器 X 已建立双向通信的其他路由器列表。这个列表包含与 X 至少达到了 2-Way 状态的所有邻居路由器,包括路由器 X 自己。接着,从列表中排除那些优先级为 0、不能成为 DR 的路由器,并按以下步骤进行计算:
- 记录网络上当前的 DR 和 BDR 数值,以便后续比较。
- 计算网络上的 BDR:在列表中,排除宣告自己为 DR 的路由器后,选择宣告自己为 BDR 的路由器中拥有最高优先级的作为 BDR;如果优先级相同,则选择标识符最大的路由器。如果没有路由器宣告自己为 BDR,则选择列表中拥有最高优先级的路由器作为 BDR,再根据标识符进行选择。
- 计算网络上的 DR:选择列表中宣告自己为 DR 的路由器中拥有最高优先级的作为 DR;如果优先级相同,则选择标识符最大的路由器。如果没有路由器宣告自己为 DR,则将新选出的 BDR 设定为 DR。
- 如果路由器 X 新近成为 DR 或 BDR,或不再是 DR 或 BDR,重复步骤 2 和 3,并排除自己参与 BDR 的选举,这样路由器不会同时成为 DR 和 BDR。
- 选举结束后,路由器按需设置新的接口状态为 DR、Backup 或 DR Other。
- 如果路由器接入的是 NBMA 网络且成为 DR 或 BDR,它需向不能成为 DR 的路由器发送 Hello 包。
- 选举导致 DR 或 BDR 变化时,需要对达到至少 2-Way 状态的邻居调用事件,以重新检查关联接口上的邻接。
这种复杂的选举算法确保在当前 DR 失效时,BDR 能顺利接替,并通过适当的滞后来进行顺利过渡。在某些情况下,可能会选举一台路由器同时成为 DR 和 BDR,或者 DR 和 BDR 的优先级不一定是最高和次高的路由器。最后,若路由器 X 是唯一可能成为 DR 的,它将选择自己为 DR 而不会有 BDR,这种情况很奇怪,但是在实际情况下确实会发生。
void Interface::elect_designated_router() {
// printf("\n\n\tStart electing DR and BDR...\n");
std::cout << "Start electing DR and BDR..." << std::endl;
std::list<Neighbor *> candidates;
// 1. Select Candidates
Neighbor self(ip_addr, this);
self.id = ntohl(inet_addr(THIS_ROUTER_ID));
self.designated_router = designated_router;
self.backup_designated_router = backup_designated_router;
candidates.emplace_back(&self);
for (auto& neighbor : neighbors) {
if (static_cast<uint8_t>(neighbor->state) >= static_cast<uint8_t>(Neighbor::State::TWOWAY) &&
neighbor->priority != 0) {
candidates.emplace_back(neighbor);
}
}
// 2. Elect DR and BDR
Neighbor *dr = nullptr;
Neighbor *bdr = nullptr;
// 2.1 Elect BDR
std::vector<Neighbor *> bdr_candidates_lv1;
std::vector<Neighbor *> bdr_candidates_lv2;
for (auto& candidate : candidates) {
if (candidate->designated_router != candidate->ip_addr) {
bdr_candidates_lv2.emplace_back(candidate);
if (candidate->backup_designated_router == candidate->ip_addr) {
bdr_candidates_lv1.emplace_back(candidate);
}
}
}
auto neighbor_cmp = [](Neighbor *a, Neighbor *b) {
if (a->priority != b->priority) {
return a->priority > b->priority;
} else {
return a->id > b->id;
}
};
if (!bdr_candidates_lv1.empty()) {
bdr = *std::max_element(bdr_candidates_lv1.begin(), bdr_candidates_lv1.end(), neighbor_cmp);
} else if (!bdr_candidates_lv2.empty()) {
bdr = *std::max_element(bdr_candidates_lv2.begin(), bdr_candidates_lv2.end(), neighbor_cmp);
} // lv2 must be not empty
// 2.2 Elect DR
std::vector<Neighbor *> dr_candidates;
for (auto& candidate : candidates) {
if (candidate->designated_router == candidate->ip_addr) {
dr_candidates.emplace_back(candidate);
}
}
if (!dr_candidates.empty()) {
dr = *std::max_element(dr_candidates.begin(), dr_candidates.end(), neighbor_cmp);
} else {
dr = bdr; // emmm...
}
auto old_dr = designated_router;
auto old_bdr = backup_designated_router;
designated_router = dr->ip_addr;
backup_designated_router = bdr->ip_addr;
// designated_router = dr->id;
// backup_designated_router = bdr->id;
// If DR/BDR changed
if (old_dr != designated_router || old_bdr != backup_designated_router) {
for (auto& neighbor : neighbors) {
// rfc2328中说,一旦DR/BDR改变,就要检查是否需要建立(2-way->exstart)/维持(any->2-way)邻接
if (neighbor->state >= Neighbor::State::TWOWAY) {
neighbor->event_adj_ok();
}
}
}
if (dr->ip_addr == ip_addr && designated_router != ip_addr) {
MAKE_NETWORK_LSA(this);
}
// printf("\n\tnew DR: %x\n", designated_router);
// printf("\n\tnew BDR: %x\n", backup_designated_router);
// printf("Electing finished.\n");
std::cout << "\tnew DR: " << ip_to_str(designated_router) << std::endl;
std::cout << "\tnew BDR: " << ip_to_str(backup_designated_router) << std::endl;
std::cout << "Electing finished." << std::endl;
}
最短路径计算
最短路和路由表的计算参考RFC 2328的16节完成。
解析LSA并构造结点和边
路由表的计算需要解析LSA内容,如下:
- 所有LSA都有一个相同的
Header结构,用于描述LSA的基本信息。在不同的LSA中,link_state_id的含义不同。在Router LSA中,link_state_id为生成该LSA对应的路由器ID;在Network LSA中,link_state_id为该网段DR的接口IP地址。 Router LSA由每个配置了ospf的路由器生成,描述该路由器接入该区域的接口,称为Link。如果网络类型均为Transit,因此link_id为DR的接口IP地址,link_data为关联(对端)接口的IP地址。Network LSA由DR生成,描述该网段的接入路由器。Router LSA没有直接描述网络。可以通过Network LSA找到对应的路由器ID。Summary LSA由区域边界路由器(ABR)生成,描述ABR与其他区域的连接。link_state_id为区域外网段,报文内有metric字段,表示ABR到该网段的代价,netmask字段表示该网段的子网掩码。ASBR Summary LSA和AS External LSA描述了ASBR的连接和外部网络的连接。
在用dijkstra算法计算最短路径时,需要构造结点和边的信息。在本实现中为了方便起见,结点id定义与RFC 2328的附录E稍有不同。
结点定义如下:
struct Node {
in_addr_t id;
in_addr_t mask = 0;
uint32_t dist;
Node() = default;
Node(in_addr_t id, uint32_t dist) : id(id), dist(dist);
Node(in_addr_t id, in_addr_t mask, uint32_t dist);
bool operator>(const Node& rhs) const noexcept;
};
结点并不单纯是路由器,因为最终要维护的路由表的目的地址是相应网段。因此有两种结点类型,通过mask是否等于0来区分。对于网络结点,id为网段,mask为子网掩码;对于路由器结点,id为路由器ID,mask为0。dist为到达该结点的距离。存根网络区域也按照网络结点的方式处理。
特殊定义大于号,用于dijkstra算法堆排序中std::priority_queue的比较。
边定义如下:
struct Edge {
in_addr_t dst;
uint32_t metric;
Edge() = default;
Edge(in_addr_t dst, uint32_t metric);
};
边仅表示出边,dst为目的结点id,metric为到达该结点的代价。对于路由器结点而言,往往出边和入边成对出现;但对于网络结点,其仅有入边,且metric为0。存根网络区域视为特殊的网络结点,但其入边metric不为0。
通过以下代码初始化结点和边的信息:
// 从第一类和第二类LSA中记录结点信息
this_lsdb.lock();
for (auto& lsa : this_lsdb.router_lsas) {
// 对路由器结点,ls_id为其路由器id
nodes[lsa->header.link_state_id] = {lsa->header.link_state_id, UINT32_MAX};
// 记录路由器结点的出边
for (auto& link : lsa->links) {
if (link.type == LSA::LinkType::POINT2POINT) {
// 对点到点网络,link_id为对端路由器id
Edge edge(link.link_id, link.metric);
edges[lsa->header.link_state_id].push_back(edge);
} else if (link.type == LSA::LinkType::TRANSIT) {
// 对中转网络,link_id为该网络dr的接口ip
// 因此需要查Network LSA找到所有对应的网络结点
auto nlsa = this_lsdb.get_network_lsa(link.link_id);
if (nlsa == nullptr) {
continue;
}
for (auto& router_id : nlsa->attached_routers) {
if (router_id == lsa->header.link_state_id) {
continue;
}
Edge edge(router_id, link.metric);
edges[lsa->header.link_state_id].push_back(edge);
}
} else if (link.type == LSA::LinkType::STUB) {
// 对stub网络,link_id为网络ip,link_data为mask
// 需要新建一个结点
nodes[link.link_id] = {link.link_id, link.link_data, UINT32_MAX};
Edge edge(link.link_id, link.metric);
edges[lsa->header.link_state_id].push_back(edge);
}
}
}
for (auto& lsa : this_lsdb.network_lsas) {
// 对网络结点,id本来是dr的接口ip,可能与路由器id相同
// 因此这里将网络结点的id按位与其mask,并用mask区分是否是网络结点
auto net_node_id = lsa->header.link_state_id & lsa->network_mask;
nodes[net_node_id] = {net_node_id, lsa->network_mask, UINT32_MAX};
// 路由器到网络结点的入边,距离为0
for (auto& router_id : lsa->attached_routers) {
Edge edge(net_node_id, 0);
edges[router_id].push_back(edge);
}
}
this_lsdb.unlock();
在处理Router LSA时,需要通过link_id找到对应的Network LSA,再通过link_data找到对应的路由器ID。metric为该链路的代价,即路径计算中的权重。
第3-5类的LSA的解析和构造较为简单,在最短路算法执行完毕后加入,因为其主要获取的是由区域边界路由器(ABR)和自治域边界路由器(ASBR)生成的路由汇总。Summary LSA的加入如下:
// Summary LSA
this_lsdb.lock();
// 构造区域间路由
for (auto& lsa : this_lsdb.summary_lsas) {
// 如果是自己的LSA
if (lsa->header.advertising_router == ntohl(inet_addr(THIS_ROUTER_ID))) {
continue;
}
auto it = nodes.find(lsa->header.advertising_router);
// 如果不存在
if (it == nodes.end()) {
continue;
}
auto abr_node = it->second;
// 如果不可达
if (abr_node.dist == UINT32_MAX) {
continue;
}
// 路径长度不需要加lsa的metric
Node net_node(lsa->header.link_state_id, lsa->network_mask, nodes[abr_node.id].dist); // + lsa->metric);
nodes[net_node.id] = net_node;
Edge edge(net_node.id, lsa->metric);
edges[abr_node.id].push_back(edge);
prevs[net_node.id] = abr_node.id;
}
this_lsdb.unlock();
Dijkstra算法
这里用堆实现了$O((V+E)\log V)$的Dijkstra算法,其中$V$为结点数,$E$为边数。结点和边已经在上一节进行了构造。
void RoutingTable::dijkstra() noexcept {
auto heap = std::priority_queue<Node, std::vector<Node>, std::greater<Node>>();
std::unordered_map<in_addr_t, bool> vis;
// 初始化前驱结点和访问标记
for (auto& node : nodes) {
prevs[node.first] = 0;
vis[node.first] = false;
}
// 初始化根节点
nodes[root_id].dist = 0;
heap.push(nodes[root_id]);
// 计算最短路径
while (!heap.empty()) {
auto node = heap.top();
heap.pop();
if (vis[node.id]) {
continue;
}
vis[node.id] = true;
for (auto& edge : edges[node.id]) {
if (nodes[edge.dst].dist > node.dist + edge.metric) {
nodes[edge.dst].dist = node.dist + edge.metric;
prevs[edge.dst] = node.id;
heap.push(nodes[edge.dst]);
}
}
}
}
构造路由
路由表项的定义如下:
struct Entry {
in_addr_t dst;
in_addr_t mask;
in_addr_t next_hop; // 若直连,则为0
uint32_t metric;
Interface *intf;
Entry() = default;
Entry(in_addr_t dst, in_addr_t mask, in_addr_t next_hop, uint32_t metric, Interface *intf);
~Entry() = default;
};
包含了目的地址、子网掩码、下一跳地址、距离和接口。其中下一跳地址为0表示直连,否则为下一跳对端接口的IP地址。Interface是接口的数据结构,要求保证这个指针不为nullptr。
路由表的构造如下:
// 将结点信息写入路由表
routes.clear();
for (auto& pair : nodes) {
auto& node = pair.second;
// 路由表只关心网络结点和存根网络
if (node.mask == 0) {
continue;
}
in_addr_t dst = node.id;
in_addr_t mask = node.mask;
in_addr_t next_hop = 0;
uint32_t metric = node.dist;
Interface *interface = nullptr;
// 查找下一跳的地址和自身接口
if (prevs[dst] != root_id) {
in_addr_t prev_hop = prevs[dst];
in_addr_t next_id = dst;
while (prev_hop != root_id && prev_hop != 0) {
next_id = prev_hop;
prev_hop = prevs[prev_hop];
}
if (prev_hop == 0) {
continue;
}
// 查邻居对应的接口
for (auto& intf : this_interfaces) {
auto nbr = intf->get_neighbor_by_id(next_id);
if (nbr) {
next_hop = nbr->ip_addr;
interface = intf;
break;
}
}
} else {
next_hop = 0;
for (auto& intf : this_interfaces) {
if (dst == (intf->ip_addr & intf->mask)) {
interface = intf;
break;
}
}
}
// 无论是直连还是间接,都要有接口
assert(interface != nullptr);
Entry entry(dst, mask, next_hop, metric, interface);
routes.push_back(entry);
}
在执行Dijsktra算法时,通过prevs记录了最短路径树中每个结点的前驱,通过前驱进行回溯,可以得到每个目的地址的下一跳地址和接口。
写入内核路由表
需要通过写入路由表的方式实现报文的转发功能,通过ioctl系统调用将路由表写入内核路由表中。这里需要注意的是,直连的路由表项需要先写入,否则在写入非直连路由的nexthop时会出现destination unreachable的错误。如果是直连路由,不需要设置RTF_GATEWAY标志位,因为不存在网关。
void RoutingTable::update_kernel_route() {
for (auto& entry : routes) {
rtentry rtentry;
memset(&rtentry, 0, sizeof(rtentry));
// 如果是直连,优先写入
if (entry.next_hop == 0) {
rtentry.rt_flags = RTF_UP;
}
// 设置
rtentry.rt_dst.sa_family = AF_INET;
((sockaddr_in *)&rtentry.rt_dst)->sin_addr.s_addr = htonl(entry.dst);
rtentry.rt_genmask.sa_family = AF_INET;
((sockaddr_in *)&rtentry.rt_genmask)->sin_addr.s_addr = htonl(entry.mask);
rtentry.rt_gateway.sa_family = AF_INET;
((sockaddr_in *)&rtentry.rt_gateway)->sin_addr.s_addr = htonl(entry.next_hop);
rtentry.rt_metric = entry.metric;
rtentry.rt_dev = entry.intf->name;
// 写入
if (ioctl(kernel_route_fd, SIOCADDRT, &rtentry) < 0) {
perror("write kernel route failed");
std::cout << "-- dst: " << ip_to_str(entry.dst) << std::endl;
std::cout << "-- mask: " << ip_to_str(entry.mask) << std::endl;
std::cout << "-- next_hop: " << ip_to_str(entry.next_hop) << std::endl;
} else {
// 备份
kernel_routes.push_back(rtentry);
}
}
for (auto& entry : routes) {
// 然后写入非直连
if (entry.next_hop == 0) {
continue;
}
rtentry rtentry;
memset(&rtentry, 0, sizeof(rtentry));
// 设置
rtentry.rt_dst.sa_family = AF_INET;
((sockaddr_in *)&rtentry.rt_dst)->sin_addr.s_addr = htonl(entry.dst);
rtentry.rt_genmask.sa_family = AF_INET;
((sockaddr_in *)&rtentry.rt_genmask)->sin_addr.s_addr = htonl(entry.mask);
rtentry.rt_gateway.sa_family = AF_INET;
((sockaddr_in *)&rtentry.rt_gateway)->sin_addr.s_addr = htonl(entry.next_hop);
rtentry.rt_metric = entry.metric;
rtentry.rt_flags = RTF_UP | RTF_GATEWAY;
rtentry.rt_dev = entry.intf->name;
// 写入
if (ioctl(kernel_route_fd, SIOCADDRT, &rtentry) < 0) {
perror("write kernel route failed");
std::cout << "-- dst: " << ip_to_str(entry.dst) << std::endl;
std::cout << "-- mask: " << ip_to_str(entry.mask) << std::endl;
std::cout << "-- next_hop: " << ip_to_str(entry.next_hop) << std::endl;
} else {
// 备份
kernel_routes.push_back(rtentry);
}
}
}
void RoutingTable::reset_kernel_route() {
for (auto& rtentry : kernel_routes) {
// 如果直连,不删除
if (!(rtentry.rt_flags & RTF_GATEWAY)) {
continue;
}
if (ioctl(kernel_route_fd, SIOCDELRT, &rtentry) < 0) {
perror("remove kernel route failed");
}
}
kernel_routes.clear();
}
需要编辑sysctl配置文件启用IP转发,修改/etc/sysctl.conf:
net.ipv4.ip_forward=1
修改文件后,使用以下命令使修改生效:
sudo sysctl -p
网络协议字节序问题
x86架构的CPU是小端字节序,而网络协议是大端字节序。在发送和接收数据时需要进行字节序的转换。在收发包时很多错误都是由于字节序问题引起的。
在 <netinet/in.h> 中有4个函数,其中 n 指 network,h 指 host。
uint16_t htons(uint16_t netshort);
uint32_t htonl(uint32_t netlong);
uint16_t ntohs(uint16_t netshort);
uint32_t ntohl(uint32_t netlong);
项目测试验证
仿真实验
仿真实验分为两个阶段:单接口和多接口。
其中单接口的组网如下:
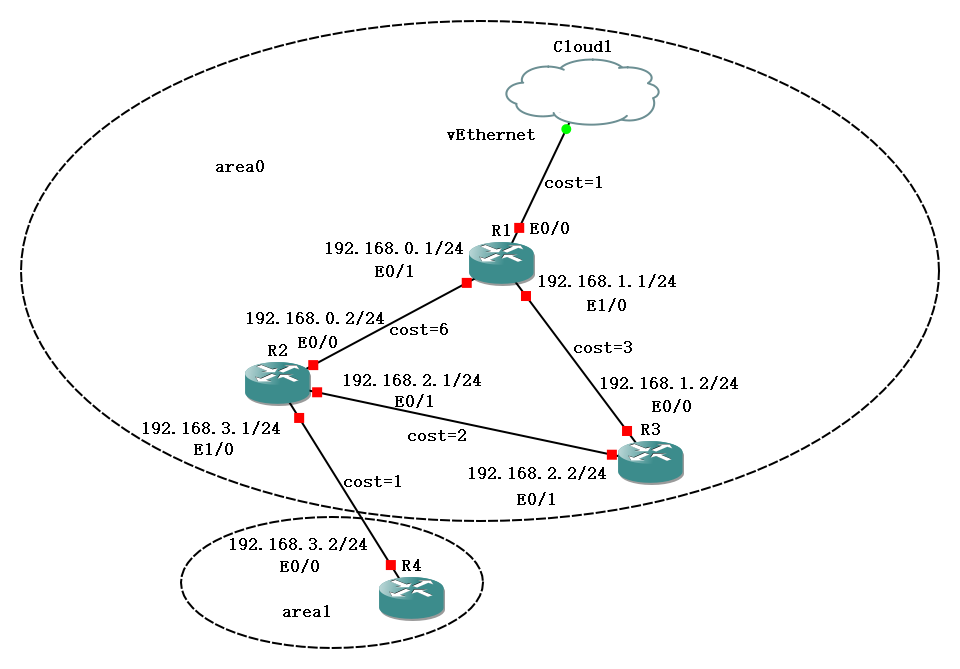
其中R2作为ABR生成area 1的路由信息,在完成同步数据库后交由实验虚拟机进行解析。
思科和华三的路由器配置命令有些不同,但是基本思路是一样的。
比如R1的配置如下:
# 思科
configure terminal
interface FastEthernet 0/1
ip address 192.168.0.1 255.255.255.0
ip ospf cost 6
no shutdown
exit
interface FastEthernet 1/0
ip address 192.168.1.1 255.255.255.0
ip ospf cost 3
no shutdown
exit
router ospf 1
network 192.168.0.0 0.0.0.255 area 0
network 192.168.1.0 0.0.0.255 area 0
# 新华三
system-view
interf G0/1
ip address 192.168.0.1 255.255.255.0
ospf cost 6
exit
interf G1/0
ip address 192.168.1.1 255.255.255.0
ospf cost 3
exit
ospf
area 0
network 192.168.0.0 0.0.0.255
network 192.168.1.0 0.0.0.255
注意思科路由器接口配置时的no shutdown是必须的,否则会出现接口未启动的情况。
./gns3目录下保存了我导出的启动配置,将配置全部导入路由器后启动即可。
单接口的实验现象要求R1和本机都达到Full状态,且ping 192.168.3.2能够ping通,tracert 192.168.3.2要求走“host->R1->R3->R2->R3”的路线。
多接口的组网如下:
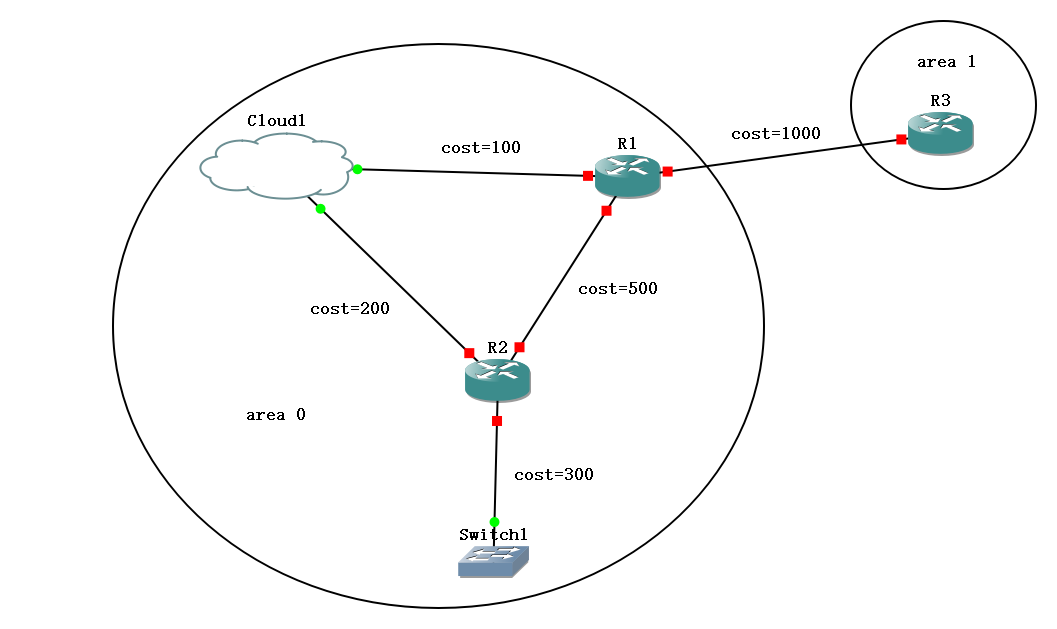
老师在群里的要求仅包括area 0部分,R3是自行添加用于检测第三类LSA的。
单接口的实验现象要求R1、R2和本机都达到Full状态,且全网ping通,从交换机S1tracert到R3要求走“S1->R2->host->R1->R3”的路线。
组网实验
线下实验组网拓扑和测试要求与上述仿真实验多接口全部一致,只不过要求R1和R2间用Serial口连接。
项目环境
编译和运行环境
环境安装
实验使用的操作系统为Ubuntu 22.04 LTS,处理器为x86_64。编译环境为g++/gcc 11.4.0,c++语言标准为c++11。通过xmake组织实验项目,但也可以通过xmake自动生成的makefile进行整个项目的编译和链接。
全部安装指令为:
# gcc/g++
sudo apt install gcc
sudo apt install g++
# make
sudo apt install make
# xmake
curl -fsSL https://xmake.io/shget.text | bash
编译和运行指令为:
# 编译
xmake # 或make
# 以root权限运行
sudo ./build/linux/x86_64/debug/ospf
编译选项
由于在源码中使用了std::thread,在linux环境下需要链接pthread,因此需要添加-lpthread的链接选项。
在debug模式添加了DEBUG的预定义,可以在代码中打印一些运行信息。
初期为了防止本机测试环境和实验室环境的不同,考虑了静态链接,通过添加-static、-static-libgcc和-static-libstdc++链接选项完成,可以通过ldd命令查看链接的程序依赖的动态链接库。在实际组网时,发现实验室提供的主机为i686处理器,而且是32位的,因此即使用静态链接的方式也无法直接拷贝运行。
xmake中更改编译选项的指令如下:
# 切换模式
xmake f -m debug/release --static=true/false
虚拟网络环境
GNS3安装
GNS3的all-in-one安装包可以在官网下载,安装过程中会自动安装Wireshark和WinPcap等所需软件。GNS3还需要一个VM虚拟机镜像来运行路由器,这个虚拟机可以是VMware、VirtualBox或者QEMU等,我用的是VMware Workstation Pro 17。GNS3官方镜像可以在这里下载。
GNS3也可以在宿主机上直接运行,但是实际测试时出现了模拟器内ping不通实体机网卡的情况,因此仍然用虚拟机运行GNS3。在运行GNS3的虚拟机时要在“编辑此虚拟机设置->处理器”里把相关的优化取消勾选。
路由器镜像
华三(H3C)给了完整的虚拟机镜像,可以在这里下载。也可以在网络上下载Cisco的路由器镜像,选则c3745和c7200两个路由器镜像。
路由器镜像在GNS3内从“Edit->Preference->IOS router”里导入即可。
GNS3联通虚拟机
需要在GNS3内添加一个Cloud节点,在Configure中勾选Show special Ethernet interfaces。如果使用WSL2进行实验测试,需要添加WSL2的虚拟网卡vEthernet;如果使用VMWare,则添加VMware Network Adapter VMnet*,VMWare的虚拟网络适配器设置为“仅主机”或NAT均可。
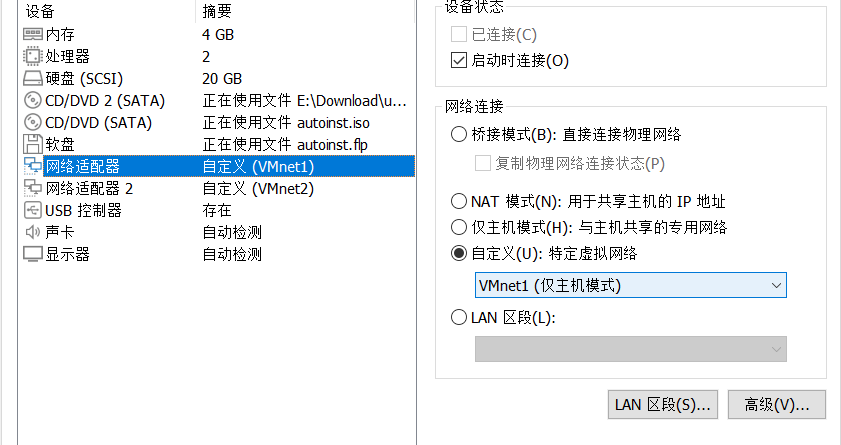
将连接到Cloud的路由器接口IP地址设置与虚拟网卡IP地址在同一子网即可,可以通过ping命令测试连通性。注意不能将IP地址设为实体机中网关的地址,会造成冲突。
GNS3配置路由器
c3745路由器默认只有两个高速以太网口,可以在“Configure->Slots”里添加更多的接口,比如NM-1FE-TX可以增加一个高速以太网口。
双网卡配置
由于WSL2的双虚拟网卡配置非常复杂,并且与实体网卡的桥接效果也不理想,因此双网卡主要使用VMWare的虚拟网络适配器完成。
搭建仿真环境时,需要首先“编辑->虚拟网络编辑器->更改设置”中将至少2个网卡设置为仅主机/NAT模式,注意要选中“将主机虚拟网络适配器连接到此网络”,这样才能在宿主机中找到该虚拟网络适配器,然后连接到GNS3的cloud。然后对运行用的虚拟机编辑其设置,添加一个网络适配器,并选择自定义,使用刚刚添加的虚拟网络适配器。
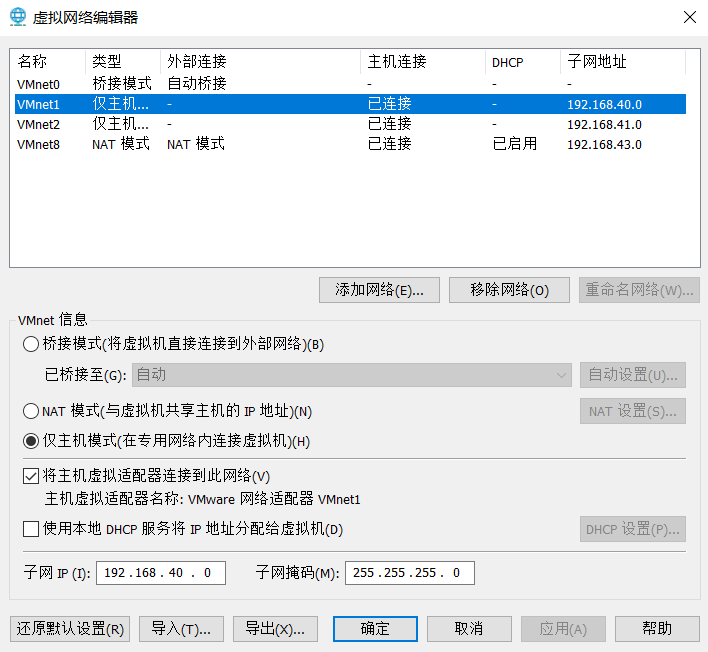
真实网络环境
组网实验桥接
以上是搭建模拟实验环境的步骤,在线下组网实验时,需要保证主机上有2个及以上的物理以太网卡(可以通过拓展坞实现),然后在VMWare的“编辑->虚拟网络编辑器->更改设置”中选择某个虚拟网卡,然后设为桥接模式,在“已桥接至”选项中选择真实的物理网卡。
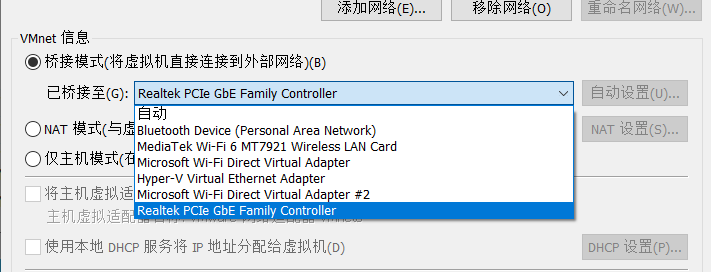
然后虚拟机编辑,将两个网络适配器调整为分别使用相应的网卡即可。对于VMNet0而言,直接使用桥接模式也可以达到同样的效果。

将宿主机和虚拟机的ip调整为同一地址,将真实的路由器的接口ip进行配置后通过ping命令进行测试。如果发现宿主机的ip地址已经被自动分配,并且在Windows下编辑网络适配器的ipv4地址无效,可以尝试将无线网络关闭后重新配置。
参考文献和项目
- RFC 2328
- frr-ospfd
- quagga-ospfd
- RuOSPFd