DragGAN论文笔记
Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold (SIGGRAPH 23)
概述
DragGAN基于StyleGAN2实现,提出了一种以用户交互的方式“拖动”图像的任何点以“编辑”图像的方法,实现GAN对生成图像的灵活、精确和通用控制。

研究现状
目标:图像合成方法实现视觉内容的可控性
- 灵活性:能够控制生成对象的空间属性
- 精确性:高精度地控制空间属性
- 通用性:适用于不同的目标类别
Unconditioned GAN
方法:
- 先验3D模型
- 手动标注的监督学习
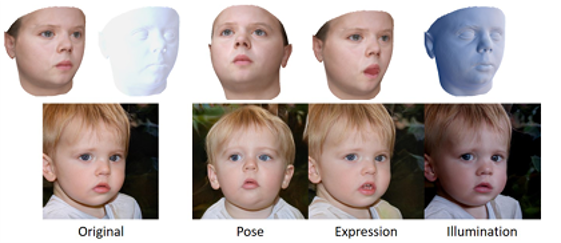
不足:
- 无法泛化到新的对象类别
- 几乎无法控制空间属性
Diffusion Models
近几年文本引导的图像生成方法,如DALL-E,CLIP等,主要基于diffusion models实现。
不足:
- 在空间上缺乏精确性和灵活性

主要方法
基于StyleGAN2的架构
基于StyleGAN2:
- 生成器部分与传统架构不同
- 建模一个图像流形(从低维隐空间到高维图像空间)
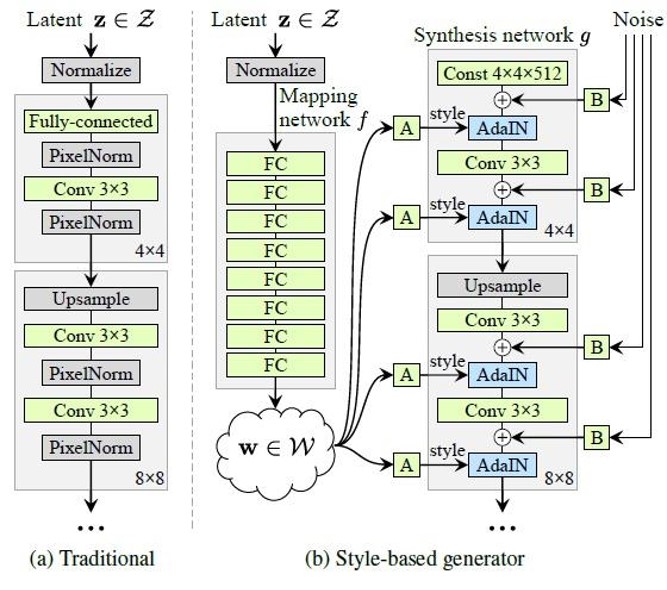
在StyleGAN架构中,一个512维的latent code z,通过8个全连接层,经过一系列仿射变换,被映射到一个中间latent code w(称为W空间)。然后w被多次复制并发送到生成器G的不同层,结合AdaIN风格迁移,以控制不同级别的属性。
简答讲一下为什么要将latent code z映射到w。我们认为一个好的风格的特征表示应该支持在latent space中的线性插值,就像下面动图中椅子从矮宽到高窄的变化。W空间的线性插值在图像空间中产生了更加连续的变化。

由于生成器G学习从一个低维潜在空间到一个高维图像空间的映射,它可以被视为在建模一个图像流形。
DragGAN整体流程
DragGAN的整体流程如下图所示。
- 输入:原始图像+多个控制点/目标点
- 输出:更新后的图像
- 子步骤:运动监督(Motion supervision)、点跟踪(Point tracking)
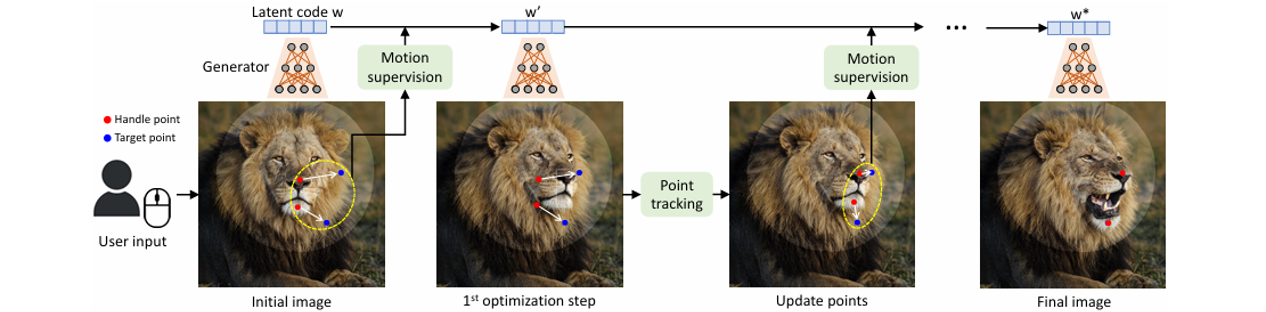
运动监督主要依靠块偏移损失实现;点跟踪这一步骤是必要的,如果没有这一步,假如我们原本想要拖拽的是狮子的鼻子,只有块偏移的话生成结果的控制点可能在狮子的脸上。对于一次拖拽,DragGAN多次进行运动监督-点跟踪的迭代。
运动监督(Motion supervision)
下图左半边为运动监督的流程。
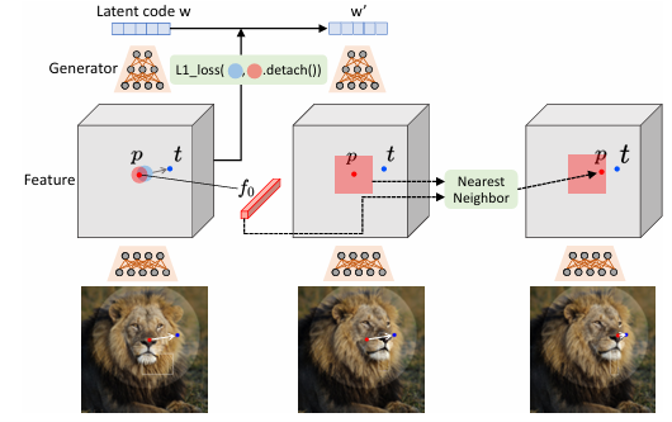
- 取StyleGAN第6个块后的特征图
- 监督控制点周围一个小区域移动到目标点周围
- 生成了一个新的隐编码
- 其中di为到目标点的向量,F表示特征图,F0为原始的特征图
只取前6层是因为图像的空间属性只与前6层相关;而且按照文章中的说法而且只到第6层的话约束少一点,更容易生成分布之外的图像,换句话说更有创造力。
这个公式第一项表示将所有控制点周围的区域移动到目标点周围;公式的第二项是为了mask服务的,保持mask外的图像区域不动。
点跟踪(Point tracking)
上图右半边为运动监督的流程。
- 更新每个操作点,使其精确跟踪对象上的对应点
- 迭代改变原始控制点
- 其中F′为新的特征图,fi为控制点的特征
进行块的移动只能说明这一块区域到达了目标区域,并不能保证控制点已经达到目标点。需要迭代地去操作控制点以到达目标点,传统的方法一般会用光流法等去寻找对应点得到控制点实质上达到的位置。然而本文对响应能力有一定的要求,引入额外的模型会有额外的开销,因此提出了一个简单的办法,直接去寻找生成后的特征图上的最近邻(实际上特征图会经过一个二次线性插值与图像的像素对应)。
实验评估
qualitative evaluation
生成编辑图片效果:
从上到下是原始图像、baseline和DragGAN的效果。可以看到DragGAN能够比较好的根据控制点的拖动来编辑图像。

真实图片编辑:
DragGAN的方法是从latent code的角度来生成图像。通过将真实图像映射到latent code空间,可以实现对真实图像的编辑。

quantitative evaluation
面部特征点拖动:
之所以选取面部是因为目前面部特征识别已经非常发达,工具非常多也非常准确。在第一个定量实验中,随机选取两张图片,将它们对应的特征点选为控制点和目标点以模拟用户输入,最后测定结果控制点和目标点的距离,可以从可视化的结果中看到baseline的控制点和目标点仍有一定距离,DragGAN的表现就比较好。

从指标上看,DragGAN的偏离和FID都更好。
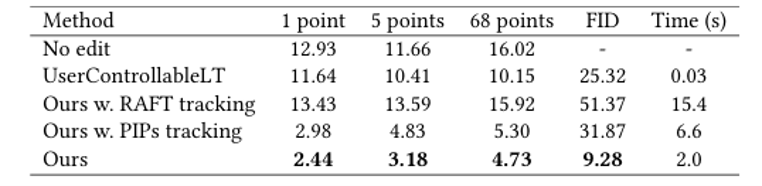
成对图像重建:
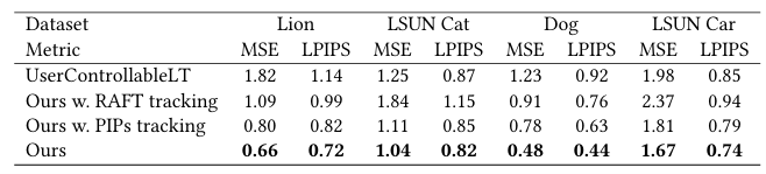
第二个定量实验,成对图像重建实际上并不是在做一个像vae那样的重建任务,它本质上是选取了一个合理的latent code w1,随机扰动得到另一个合理的w2,然后从w1中采样得到输入图片,w2中采样得到gt,从这两张图的流形中随机抽取像素作为用户输入,然后进行gt的重建。所以这个任务本质上还是在评测模型拖动的能力。从上表可以看到DragGAN的效果,MSE直接评价重建效果,LPIPS(Learned Perceptual Image Patch Similarity, LPIPS)是指学习感知块相似度,它更符合人类的感知情况。可以看到DragGAN在这两个metrics上都表现更好。
不足
训练数据分布的问题
尽管文章中说对于out-of-distribution的编辑,DragGAN有一定的创造性,但是这种创造性比较有限。如下图张大嘴的狮子确实能将狮子的嘴开得非常大,但是右边增大车轮就造成了不自然的形变。

数据问题是很多生成对抗网络的通病,由于StyleGAN的数据中大部分手臂和腿部是向下的,编辑朝向超出分布的姿势在如图手部造成扭曲的人工痕迹。

纹理缺失图像的问题
如上子图b所示,这是由于图像区域缺少纹理造成的问题。在无纹理区域的控制点(红色)在追踪过程中,图像生成可能会有更多的漂移,我们可以看到在b图中蓝点相对于后视镜其实相对位置出错了。
总结
总体来说DragGAN提出了一种全新的控制思路,通过交互式的方式来编辑图像。在实际应用中,图像生成的粘连和抖动都比较少,生成的图像质量也比较高,用运动监督和点跟踪等简单的方法实现了比较好的效果。